
The Ornstein-Uhlenbeck Process - A deep dive - Part 3 (with code)
In this series we learn all sorts of theory on the OU-Process, code it all up and use it in stat arb.

Simulated Results
Time to put the theory we learned so far to test.
Let’s do some simulations first.
We are gonna create an OU Process with the following parameters:
theta = 0.1, mu = 1, sigma = 0.01

We pretend that this is an asset price or a portfolio price.
Let’s do a simple backtest for different thresholds:
We long/short at 0.999/1.001 up to 0.95/1.05 and exit at the mean.
We are gonna use a lot more data though, 1000000 data points in total to be exact. This way our results are more accurate.
pnls = []
for entry in np.arange(0.001, 0.051, 0.001):
equity = [1]
long = False
short = False
for i in range(len(OU)-1):
if not long and OU[i] <= mu-entry:
long = True
if not short and OU[i] >= mu+entry:
short = True
if long and OU[i] >= mu:
long = False
if short and OU[i] <= mu:
short = False
ret = (OU[i+1]-OU[i])/1000
if long:
equity.append(equity[i] * (1+ret))
elif short:
equity.append(equity[i] * (1-ret))
else:
equity.append(equity[i])
pnls.append(equity[-1])
Those results are pretty obvious but ofc we have fees in the real world. Let’s introduce 0.01 of fees:

Since we have a fee for both entry and exit our total fee is 0.02 per trade.
So it looks like if we want to maximize returns then we should enter just above our cost to trade.
The further we enter beyond our cost the smaller our returns are but the more consistent our profits are since we are more likely to have mean reversion.
At this point it becomes a portfolio optimization problem since now it’s about your preferences.
Do you want to maximize returns? sharpe? minimize drawdowns? etc.
Changing Variance
So far we’ve assumed that variance is constant but that’s far from true.
In real markets volatility is mean reverting and clusters.
I go over some stochastic volatility models in the following thread:
https://twitter.com/Vertox_DF/status/1656432681528307714
I’m gonna be using the Heston Model now because it’s so similar to a OU-Process:

here v stands for our variance, theta is our mean reversion speed, omega is our mean and xi is basically the variance of our variance.
I’m gonna use the following parameters:
v[0] = 0.03, theta = 0.03, omega = 0.01, xi = 0.02
v = [0.03]
theta = 0.03
omega = 0.01
xi = 0.02
for i in range(1000):
dv = theta*(omega-v[i]) + xi * math.sqrt(v[i]) * np.random.normal()
v.append(v[i] + dv)
v[i+1] = max(0, v[i+1])
Let’s now use this instead of the sigma for our OU-Process:
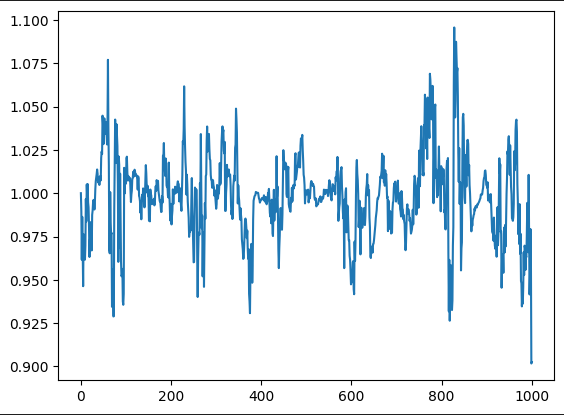
That looks a lot more like a realistic spread now! Let’s use 10000 data points now:

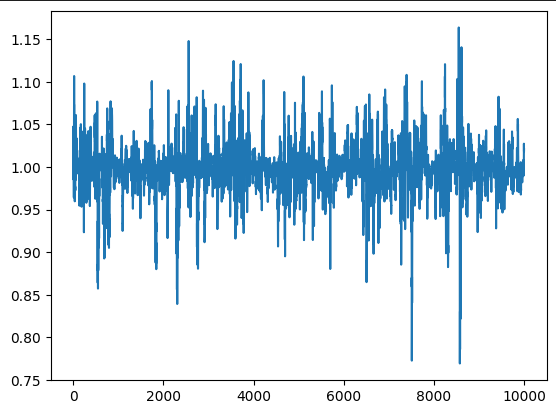
That looks pretty close to some of the stuff you see irl, missing the large legs though. We could replace the normal in the Heston Model with a laplace distribution.
Here is what that looks like:

Even better. Next thing we can change is having a mean that changes a little throughout time, that is very typical.
We can achieve this by generating a different OU Process and smoothing it out using for example a moving average.
Mean_OU = [1]
theta = 0.05
mu = 1
sigma = 0.003
for i in range(10000):
dX = theta*(mu - Mean_OU[i]) + np.random.normal(0, sigma)
Mean_OU.append(Mean_OU[i] + dX)
Mean = [1]*1000
for i in range(1000, len(Mean_OU)):
Mean.append(sum(Mean_OU[i-1000:i])/1000)
Plugging this into our OU-Process we get:

Getting closer and closer to real market behavior. You can now run a bunch of simulations and tests on this.
What behaves like this?
Generally, the more closely related 2 assets are the nicer it’s spreads statistical properties become. It starts behaving like White noise or an OU-Process or similar.
If on the other hand you have assets that aren’t strongly linked together like for example 2 different coins then you can’t expect things to behave like this and it becomes much much harder.
An example of where things do behave like this could be the basis between futures and spot/perp.
You could model that and optimize a cash-and-carry arb.
Final Remarks:
As usual the files are available on discord.