Volatility Forecasting using Neural Networks
Separating the hype from what actually moves the needle

Today, we are gonna look at something we’ve never done in any article before: Neural Networks.
Neural networks have a bad reputation in the quant finance community, and I constantly see people skip papers with titles like “Volatility Forecasting using Neural Networks” immediately. The reason is usually some version of: black-box, overfits, needs more data than any of us actually have, traditional models are more robust.
First things first, we will be clearing up some of the common misconceptions and giving them a chance, like proper researchers. Next, we will talk about the specific model architecture used in this article, why forecasting in log-space turns out to improve performance, and how we selected a final model without overfitting. Finally, we’ll put the model to the test against a simple traditional baseline model commonly used for volatility forecasting.
I write about quantitative trading the way it’s actually practised:
Robust models and portfolios, combining signals and strategies, understanding the assumptions behind your models.
Topics I write about include portfolio construction, market making, risk management, research methodology, and more.
If this way of thinking resonates, you’ll probably like what I publish.
What you’ll learn
Why the usual complaints about neural networks in finance hold up far less than people assume, and where they’re actually right.
How a NARX architecture works, and how to apply it to volatility forecasting.
Why forecasting realized volatility in log-space improves training stability and accuracy, even when your loss function (QLIKE) is already designed to be scale-robust.
How to tune and select a model, including catching when a network is overfitting.
How to interpret a trained network’s predictions using SHAP, instead of treating it as an unreadable black box.
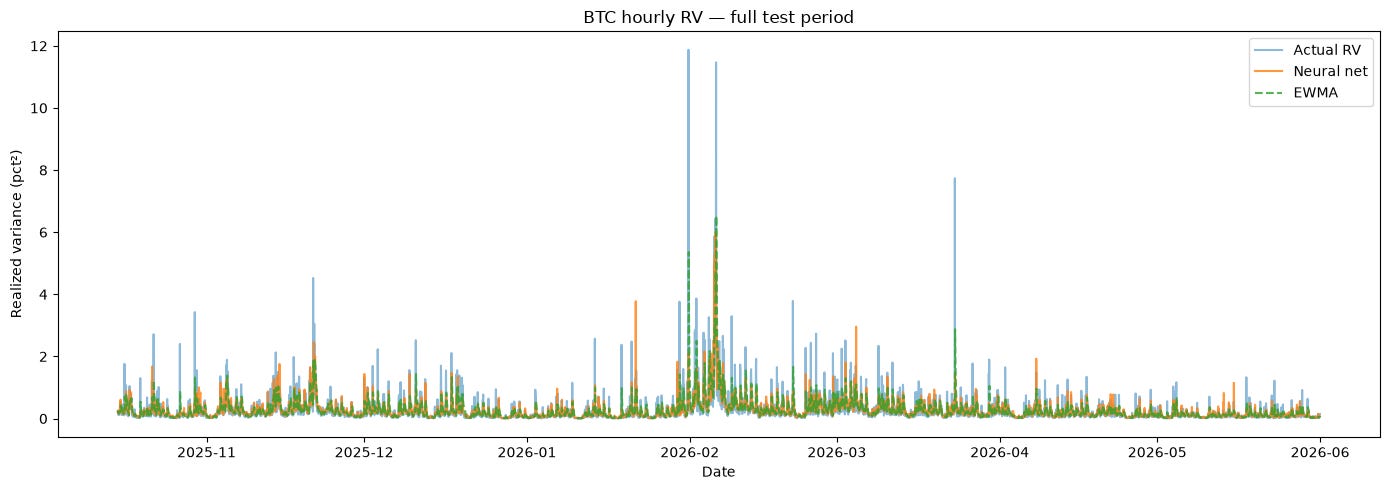
A full comparison against a tuned EWMA and persistence baseline.